
In our work at The Scale Factory, we help teams from a range of backgrounds: they might work for anything from large firms to startups; be cloud novices or cloud natives. Some teams look after 100% serverless workloads; others run everything on servers.
Nearly all the teams we work with use AWS VPC networking—we specialize in working with the AWS cloud, and lots of AWS services require a VPC. There’s an even bigger set of services that support VPC networking as an option. With that in mind, I’m going to discuss how I think about packet filtering in VPC networks, and compare it to another mental model that I don’t think works so well.
By the end of the article, I hope you’ll see why I prefer my model and why it helps you make effective choices at design time.
Starting point
First, I want to remind you about what goes into a security group: network interfaces. Here are 4 EC2 instances that each has one elastic network interface:

Some EC2 instances, each with an ENI
Back when AWS introduced VPC networking, these were always ENIs that belonged to EC2 instances, and that’s what I’ve drawn here. In 2021, many more things had network interfaces, including:
- Hosted services such as NAT Gateways
- Lambda functions that are running in a VPC (update: Lambda now uses Hyperplane ENIs)
- ECS tasks and EKS Pods running in Fargate
- VPC endpoints / PrivateLink
What’s great about the API design here is that the same security group abstraction still applies, even as AWS add new features and even address families (IPv6 was added in 2017).
Let’s add an elastic load balancer to expose those 4 EC2 instances. (I’m not drawing any security groups yet). Specifically, I’ll add a Network Load Balancer:

Filtering rules
Let’s say these instances run an online game. Most players are honest but some try hard to cheat. The threat model considers each instance as a trust boundary and I want to defend against lateral attacks, so traffic is only allowed if it comes from the load balancer (the load balancer also acts as a filter by only forwarding TCP traffic on a specific port).
I’m able to look up the IP address of the load balancer, so I can write rules that allow traffic just from its IP addresses, and only to the TCP port the instances are listening on.
Security group config #1
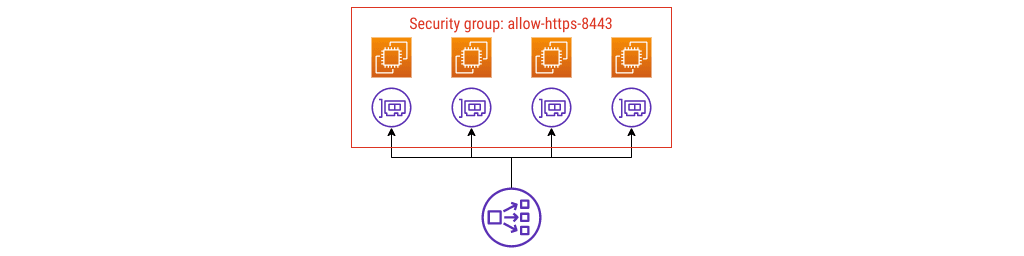
A common anti-pattern
I see this (anti-)pattern quite often; it’s this misconception I want to talk about. First of all, it’s not wrong. You can do this, your traffic comes in, AWS Support aren’t going to contact you and tell you to fix it.
I don’t think it’s the right model, though. Here’s why: the name.
That security group is called allow-https-8443, and it shouldn’t be.
You can skip ahead to my approach if you like. Before I explain that, though, I’m going to add enough extra detail to show part of the problem.
Here’s a new requirement:
- As well as allowing in game traffic, you want to support an OpenMetrics
scrape on TCP port 9999. With a defense-in-depth security posture in mind,
you configure
nftableson each instance, and you also need to use security group rules to allow the scrape traffic in.
Security group config #2
Building on config #1, I’m going to remain firmly in anti-pattern land and define another group, allowing traffic in on port 9999.
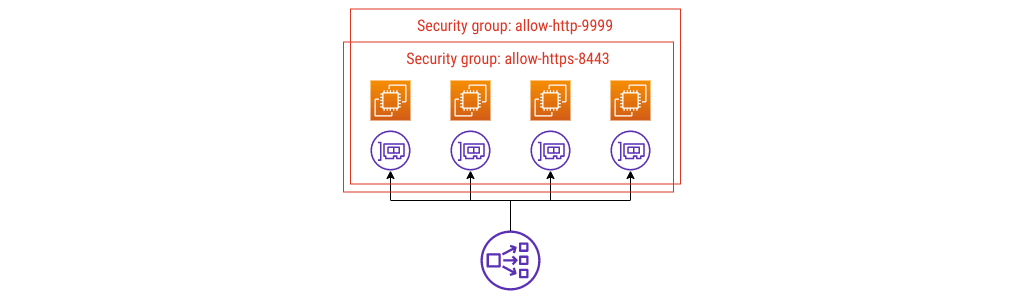
Still an anti-pattern
Now the instances allow OpenMetrics scrapes too. I’m going to add some ECS tasks to represent a monitoring product – these could be Prometheus, or Grafana Agent.
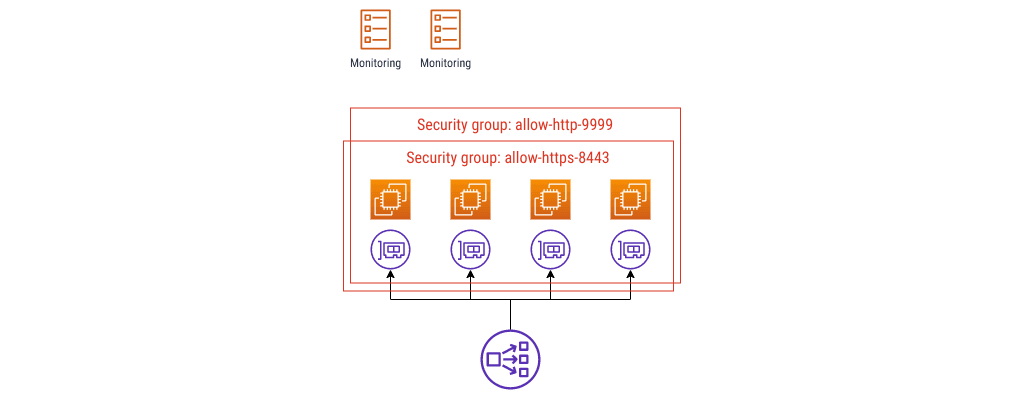
This is where the naming gets into a bit of pickle, at least in my experience. If you have something like this already, what might happen is a security review turns up that the webservers allow port 9999 from anywhere, or maybe from the whole VPC, and this doesn’t meet a least-privilege access rule control that you need to show you’re doing.
You can put a security group around those ECS tasks, and you can call it
something like allow-egress-9999, and you can allow ingress to the webservers
from that group.
Bear in mind that this is only good for up to 16 security groups, then you hit a hard limit. The bigger problem, for me, is that these group names all say what they do, not what they’re for. It’s a pain if you need to change the rules in place, because you can’t rename an existing group. Plus, if you ever have to troubleshoot the rules or justify each one, it takes more effort than you’d like. A lot more.
Security group config #3
Here’s my architectural fix: change the names.
I’m going to call that first group game-servers-production:

Using the name game-servers-production immediately tells you what you’ll
find in that group: production game servers.
When you need to scrape metrics, you can put those ECS tasks in their own group. Let’s do that.
Security group config #4
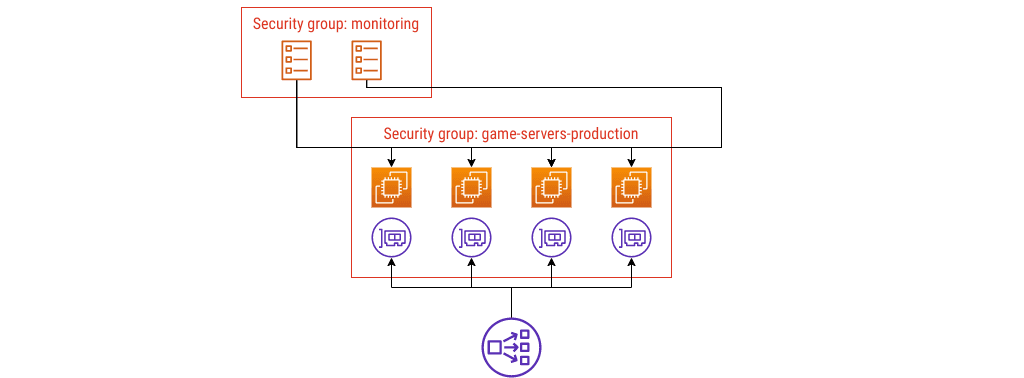
I named these security groups a bit like in a Venn diagram: by what they enclose. I haven’t drawn the rules in yet, but you could imagine annotating the lines between groups with details of the port, protocol, and anything else you need to show.
Security group config #5
I picked a Network Load Balancer earlier to keep things simple, but more commonly you would use an Application Load Balancer. If you did, you’d need another security group, something like this:
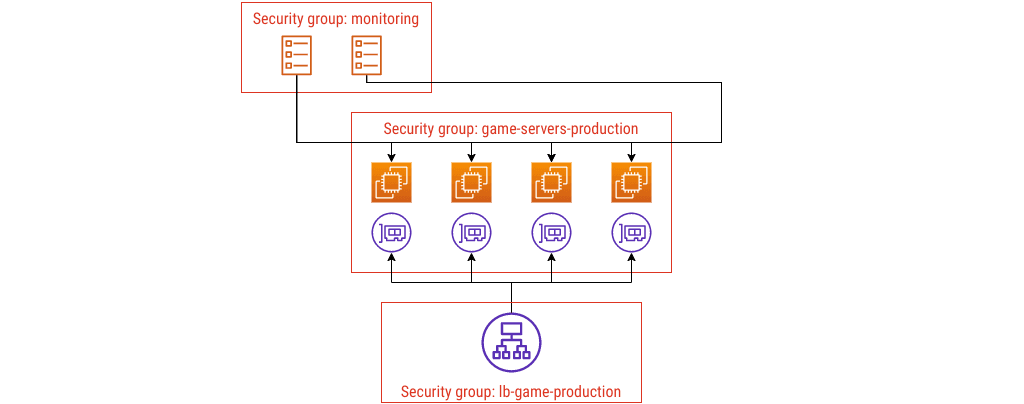
Again, the name lb-game-production tells you what it is. If you change the ports
you’re using – maybe you need to support port 80 because people try connecting
with plain HTTP – the name you use still describes what you’ve deployed.
When you see it drawn out like that, it probably feels obvious, right? I made all these diagrams to make it this explicit, because I know when you’re looking at just one part of some Terraform HCL or CloudFormation YAML, the snags in the design don’t jump out at you the same way.
Self-documenting infrastructure
First, an aside: if you’re picturing containers and EC2 instances that write their own READMEs, this isn’t the article you wanted. What you can do, though, is use fields in AWS’ own API to hold some of that documentation.
Security group rules have a description field; so do the groups themselves. This is like code comments but even better: not only does that information live in the source code where you define the groups and rules, but it’s right there in the API as well.
If you get audited for IT and one of the controls is “all firewall rules must have a justification”, try to fit as much of that detail as you can in the description as well. Naming your groups after what they contain fits into this really well.










