
Terraform is an extremely powerful tool, but with great power comes great opportunity to break stuff, or whatever Uncle Ben said. With a single command a developer can deploy hundreds of resources in an instant, and when that developer inevitably configured the inputs wrong Terraform makes it easy to patch or rollback that mistake. But you know what’s better than recovering from mistakes? Never making the mistake in the first place.

Let’s imagine for a second that I’m new to Terraform…
My company Widget Co. have decided that there is a giant untapped market in selling our widgets direct to consumers and so are gearing up to launch a new web store. Being a greenfield project we have the opportunity to use the latest and greatest tools and practices like Infrastructure as Code and Terraform. Company executives expect several million sales in the first week so our infrastructure also has to be scalable. With that in mind I write the following Terraform:
variable "ami" {
description = "ID of the AMI to use for our auto scaling group"
}
variable "environment_cost_allocation" {
description = "Environment of the deployment."
default = "dev-test"
}
resource "aws_launch_template" "app_lt" {
image_id = var.ami
instance_type = "t2.micro"
}
resource "aws_autoscaling_group" "app_asg" {
availability_zones = ["eu-west-1a"]
max_size = 100
min_size = 1
launch_template {
id = aws_launch_template.app_lt.id
version = "$Latest"
}
tag {
key = "environment"
value = var.environment_cost_allocation
propagate_at_launch = true
}
}
All it does is take our pre-made app AMI and deploy it to an AWS auto scaling group. Super simple so surely nothing can go wrong…
Validating Input with Custom Rules
Another one of these amazing new practices we have on this greenfield project is the concept of a “development” environment, no more deploying straight to production. I write up a development.tfvars file to keep my inputs separate:
ami = "ami-0d1bf5b68307103ca"
environment_cost_allocation = "development-test"
Feeling very confident about my choices so far I run a terraform apply which completes without complaint. While marveling at the shiny new development web store I hear the dreaded coin drop of a Slack notification. It’s the CFO who since being alerted to the existence of the powerful AWS Cost Explorer has been infatuated:
Charles F. Owens:
Hey just wanted to let you know it looks like you’ve mistakenly used the incorrect billing tags on the new dev environment. Good luck with the testing!
Charles is right: we had previously agreed to follow best practices and have a strict and consistent tagging strategy. Our plan at Widget Co. is to use the tag “environment” with a value that is either prefixed by “dev-” or matches “prod”. We’ll use that keep track of costs across our different environments. Unfortunately, I had mistakenly used the environment name “development-test” and the cost report has come out wrong.
Cursing my annoying habit of spelling words in full and acknowledging that this issue is likely to happen again I search for a solution to prevent such mistakes in future. Luckily, there is one. Terraform input variables have a feature called Custom Validation Rules that can save me from myself.
Let’s update the environment variable definition to look like this:
variable "environment_cost_allocation" {
description = "Environment of the deployment."
default = "dev-test"
validation {
condition = can(regex("^(prod|dev-.*)$", var.environment_cost_allocation))
error_message = "Environment cost allocation must match either 'prod' or 'dev-*'."
}
}
The interesting section is the validation block, which allows us to define a condition expression and error_message string. Here we use the regex function to check our input var.environment matches either the “dev” or “prod” strings. The can function is particularly useful for validation rules as it evaluates expressions and returns a boolean depending on whether the expression ran without error. In our case, if the environment variable does not match our pattern then the regex function will error which will then be converted into a false by the can function thus failing the condition.
var.environment | regex() result | can() result | Condition |
|---|---|---|---|
"prod" | "prod" | true | Passes |
"dev-test" | "dev-test" | true | Passes |
"dev-staging" | "dev-staging" | true | Passes |
"production" | Error | false | Fails |
"dev" | Error | false | Fails |
I try running terraform plan again with the same inputs:
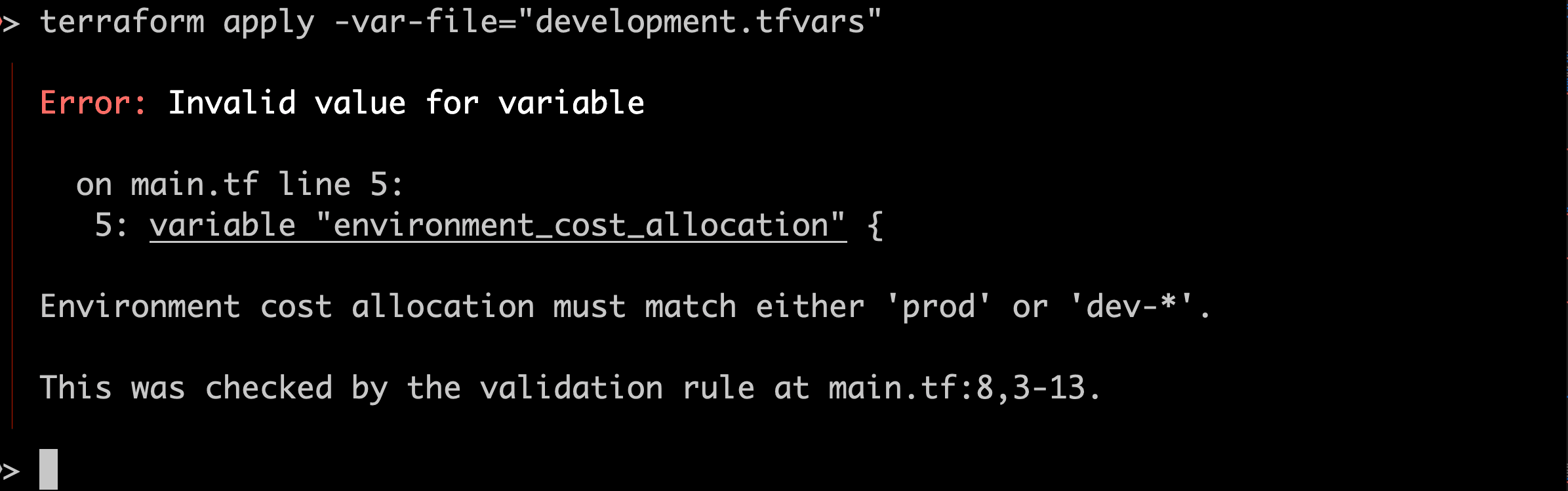
Great! The code errors correctly and we get an informative error message explaining how to fix it. Crucially, if this had been in place before I did my first apply then I never would have deployed real resources with real costs.
Advanced Usage
As seen above custom validation rules are very helpful when trying to enforce a format on an input variable but don’t forget you can use any of the Terraform expression functions for your condition. For example:
variable "ip_address" {
validation {
condition = length(regexall("\b${replace(var.ip_address, ".", "\.")}\b", file("ipallowlist.txt"))) > 0
error_message = "IP address must be listed in ipallowlist.txt."
}
}
This validation rule checks that an input IP address is present within an allow list file. If you use Terraform as part of a build pipeline, this can be extended further by generating your allow lists with other tools. However, take care with this kind of usage to avoid coupling your Terraform code to other parts of your build pipeline. Keeping your Terraform decoupled will allow developers to iterate locally faster.
Furthermore, we can extend this ip_address example further by adding a second validation block that checks that the input value is a validly formatted IPv4 address:
validation {
condition = can(cidrhost("${var.ip_address}/32", 0))
error_message = "Invalidly formatted IP address provided."
}
Using multiple validation blocks allows you to break up more complex checks, and give more specific error messages that help reduce remediation time. Here, I used the cidrhost function to do most of the validation work.
Validating Input with Data Sources
Thanks to our dev environment, the QA department catches a game stopping CSS bug: on the checkout page, the option for MasterCard and Visa payments are both invisible. Thankfully, the dev who knows CSS isn’t on holiday and they quickly build a new AMI with our updated app.
Claire S. Simmons:
G’day mate. Here’s the AMI for the updated app: ami-087c17d1fe0178315
I update the tfvars file, run a terraform apply to update the launch template and then start an instance refresh on the auto scaling group so the new AMI gets rolled out. Easy.
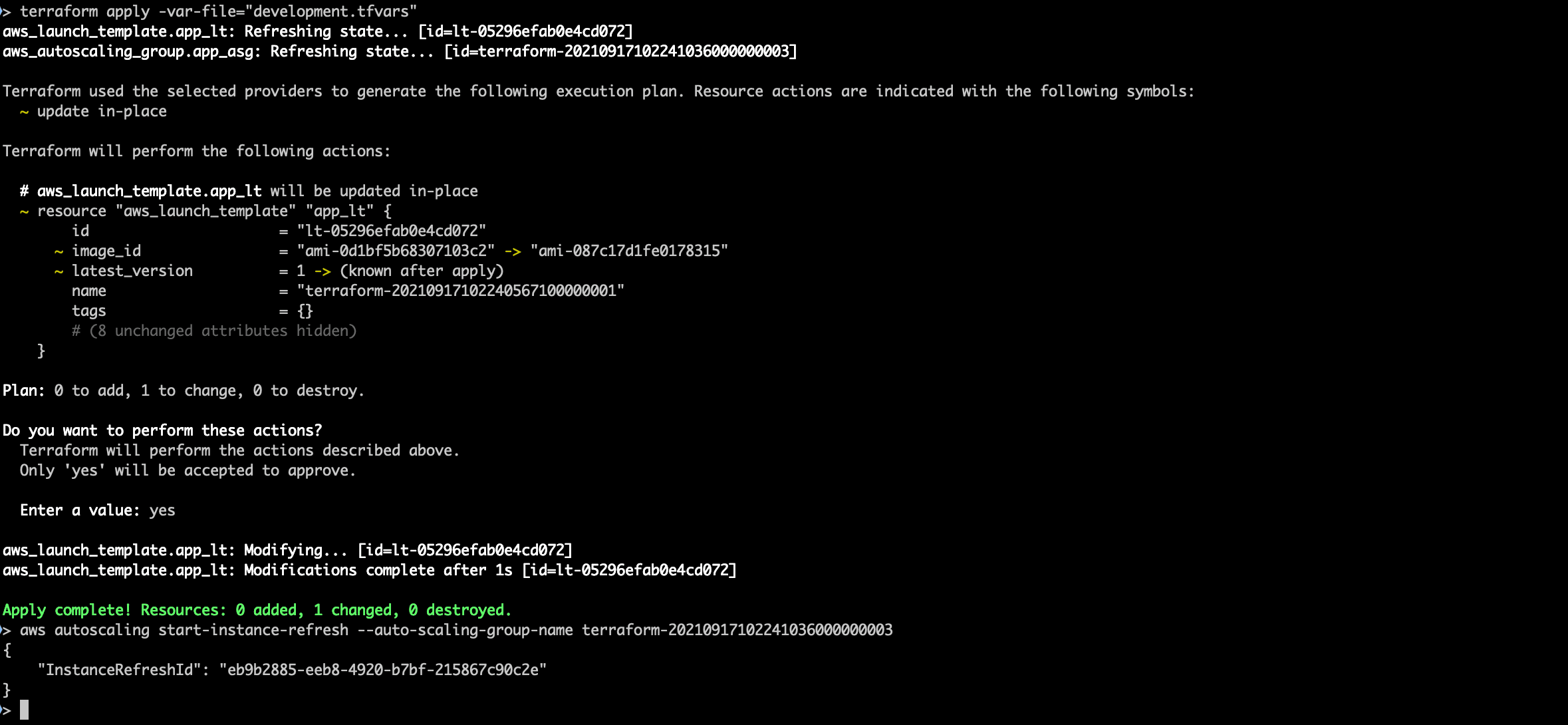
Or not. The website goes down but never comes back up. With that funny stomach feeling that only comes from an outage I head over to the AWS Console to see what’s up. I find my answer in the auto scaling group’s activity history:
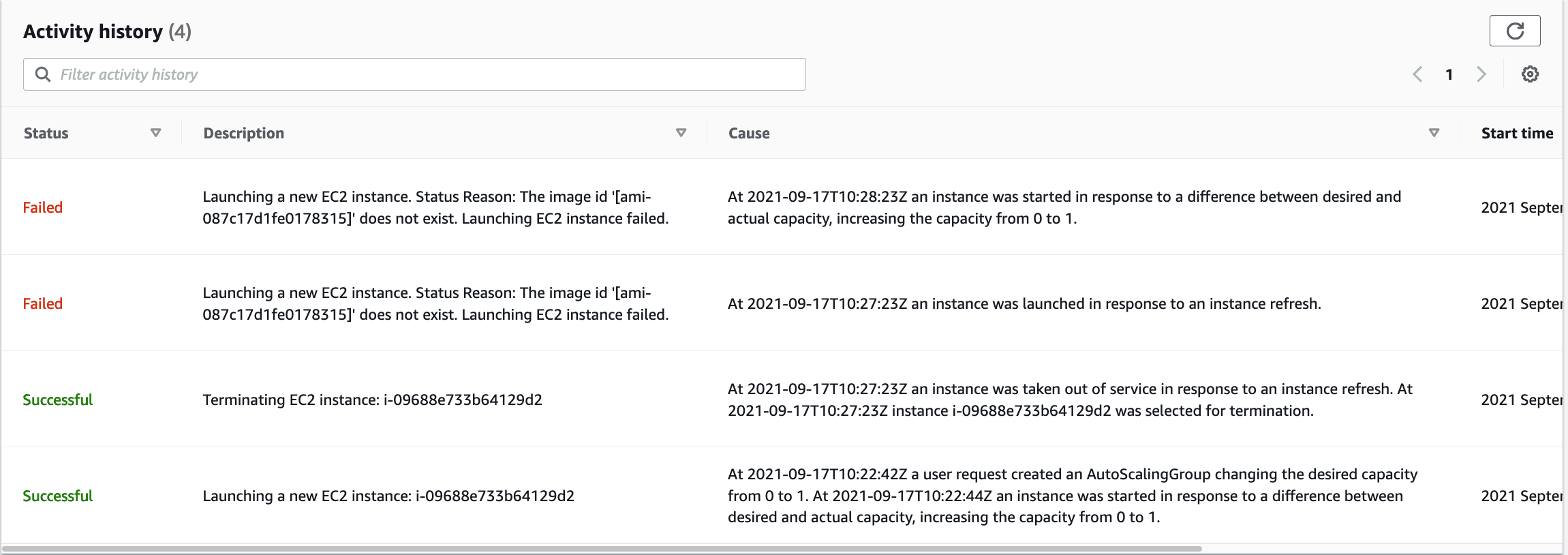
It’s complaining that the AMI doesn’t exist. Understanding dawns on me. Claire is part of the application team based in Sydney and the AMI would need to be copied over to my region to be usable. Annoyingly it doesn’t seem like either Terraform or AWS validate the launch template to check that an AMI actually exists before it gets used by my auto scaling group. Flabbergasted, I roll back the deployment and once again try to find a fix that will stop this issue reoccurring. At least I only took a development environment offline.
My first thought is to use a custom validation rule again, but I realise that would only help me validate the format of the input string and not check whether the AMI resource really exists in the real world. If only there was a way for Terraform to pull data from a provider without creating new resources… oh right there is: data sources.
Let’s add a new data source block that looks like this:
data "aws_ami" "app_ami" {
owners = ["amazon", "self"]
filter {
name = "image-id"
values = [var.ami]
}
}
Generally speaking, data sources are used to pull information about already deployed resources for integration with new resources, however, they have a characteristic that makes them useful for validating resources exist too. Data sources information is pulled during the early “refresh” stage of a Terraform plan or apply. Because this refresh stage happens before any resources are created we can use it to force an error without making changes to the state of our infrastructure.
I run a plan again with the same development inputs:
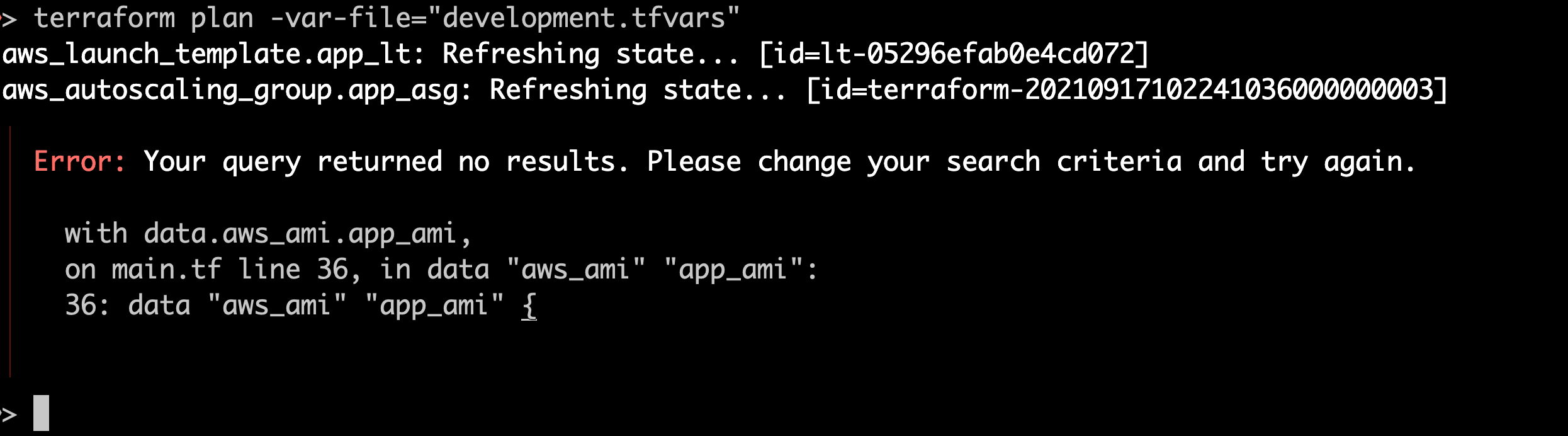
Before attempting to deploy any resources, Terraform now flags that data source as invalid, saving me quite a bit of embarrassment. I can now update the AMI variable to the correct value and deploy to dev successfully.
Advanced Usage
In the above case, this validation saves me from making a logical mistake that Terraform or AWS would not otherwise catch. However, it can still be useful to use this technique in cases where Terraform would catch the error but only after it had started deploying resources. For example, if I had been deploying just a single aws_instance resource using its ami attribute then Terraform would have thrown an error during deployment, but this could have left the infrastructure and state “broken” as it would have started deploying or changing resources already. Using the data source would allow you to fail faster and catch that error before resources are changed.
Another defensive use of data sources is when using the terraform_remote_state data source to integrate with resources in another workspace. It can be beneficial to validate that the remote state has itself not drifted by validating that its output resources exist. For example:
data "terraform_remote_state" "network_layer" {
backend = "remote"
config = {
organization = "widgetco"
workspaces = {
name = "network_layer"
}
}
}
data "aws_lb" "ingress" {
arn = data.terraform_remote_state.network_layer.outputs.ingress_lb
}
Here we check that our ingress application load balancer still exists as per the network_layer workspace. When planning our code will now error early if either the load balancer has been deleted/changed manually, or the network_layer workspace no longer outputs an ingress_lb value.
Defensive Defaults
With our development environment ticking along smoothly the company executives are eager to get our store out there in front of widget buyers. I create a new production.tfvars and run apply:
ami = "ami-087c17d1fe0178315"
Everything applies smoothly and I can soon see the widget orders rolling in. Satisfied after a successful launch I start packing up for the day. Just as I am about to close my laptop another Slack notification appears.
Charles F. Owens:
Are we selling widgets from our development environment? I’m happy we are selling stuff but I think there might be something up with the tags again…
Once again Charles is right on the money (as a CFO should be). After a bit of snooping through the console, I realise the mistake. I had not defined an environment_cost_allocation variable for the production deployment and so all of the production resources are tagged as the default “dev-test”. It occurs to me that I’d really set myself up for failure here by defining a default that wasn’t likely to be acceptable for all use cases. I decide to just remove the default entirely. Next time it will error unless I explicitly declare an environment.
Thankfully this time this problem manifested itself benignly as a tagging issue. I consider what the ramifications could have been if I’d used development defaults for something like firewall rules…
After fixing the production tags I can finally close my laptop and start to think about all the improvements I can make tomorrow.










