
As a cloud service provider, you’re responsible for making sure that the application code, the infrastructure to run it, and your customers’ data are all available when your customers expect them to be.
You can make use of the security controls already available from your cloud infrastructure provider to help secure your workload. Here’s an example of that for AWS.
Cloud access management
For SaaS — software as a service — offerings on AWS, one of the main information security controls you’ll use is IAM (AWS Identity & Access Management). Pretty much every AWS service lets you control who can do what with that service using IAM permissions. Many cloud services let you set fine-grained access controls, and I’ll talk more about that below.
IAM lets you manage access to resources, based on their ARN (ARNs are basically like URLs, except that Amazon invented their own alternative). An IAM policy lets you grant or deny access so that a principal can or can’t access a resource.
Here’s an example policy (JSON format) with each of those elements:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": [
"arn:aws:iam::123456789012:root"
]
},
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:GetObjectVersion",
"s3:DeleteObject",
"s3:DeleteObjectVersion"
],
"Resource": "arn:aws:s3:::your-bucket/*"
},
{
"Effect": "Allow",
"Principal": {
"AWS": [
"arn:aws:iam::123456789012:root"
]
},
"Action": "s3:ListBucket",
"Resource": "arn:aws:s3:::your-bucket"
}
]
}
It looks complex if you haven’t seen one of these before, so I’ll explain what each bit does. The policy has at least one Statement (the order matters). In a Statement, Effect is either Allow or Deny. Principal and Action describe the scope of that Effect, and Resource is the thing you want to control access for.
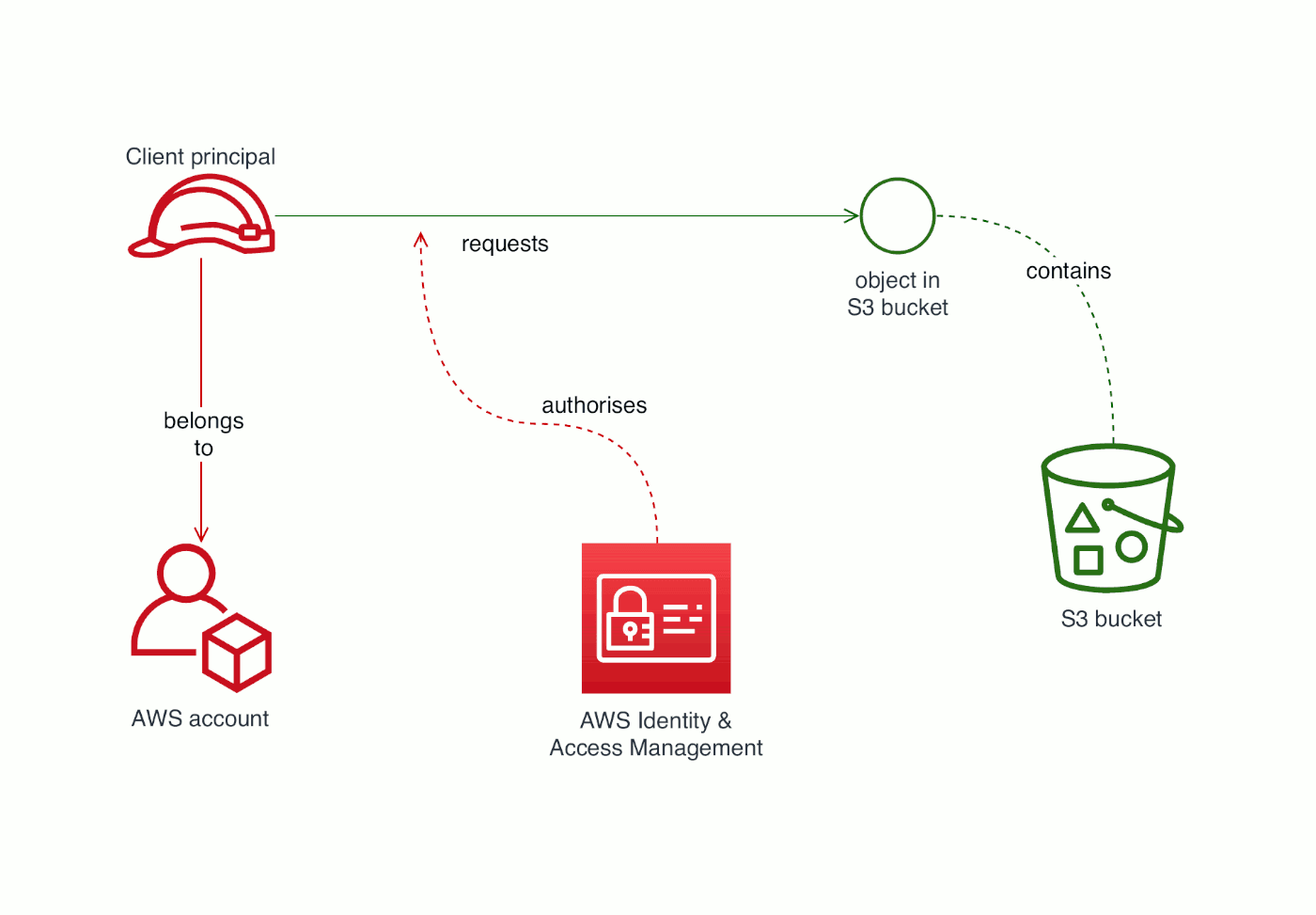
S3 bucket access granted to an AWS account
Your customers want to take information security for granted: they’re paying you to take care of these details so that they don’t have to. One way to help make systems secure is to isolate users into different tenancies.
There’s a problem with the first IAM policy though. It’s granting access to an entire AWS account. You might do that if you run each tenant in its own AWS account for isolation. Even if you are using accounts that way, it’s rarely good practice to grant access to an entire account.
IAM roles let you create an authorisation principal for a particular purpose. Roles aren’t the only kind of IAM principal, but they’re the most appropriate way to divide and restrict access so you can keep your application secure. Even when you have IAM users and groups for your own IT team, it’s good practice to let group members assume an administrative role with time-limited session access. I’ll cover role assumption again later on.
Tenant isolation using IAM policies
I’m going to revisit the S3 bucket with your clients’ data in it. Because you want to make sure that different tenants are kept apart, you can treat an S3 bucket as a pooled resource and partition it based on prefix. Here’s an excerpt from a bucket policy you could use for that:
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:GetObjectVersion",
"s3:DeleteObject",
"s3:DeleteObjectVersion"
],
"Resource": "arn:aws:s3:::your-bucket/example-tenant/*"
},
{
"Effect": "Allow",
"Action": "s3:ListBucket",
"Resource": "arn:aws:s3:::your-bucket",
"Condition": {
"StringLike": {
"s3:prefix": [
"example-tenant/*"
]
}
}
}
…why wouldn’t you want to create an S3 bucket for each client? You might, if you only have a few, security-conscious customers. AWS limits the number of S3 buckets you can have in one account. If you plan to have hundreds, thousands, or millions of tenants, you’ll need another approach.
A number of The Scale Factory’s clients provide SaaS applications with high assurance requirements; typically these are about healthcare records or financial data, or the product is used for handling payments. Those clients want to be sure that each tenant’s end users cannot ever access the data from another tenancy.
A traditional way to ensure isolation was to partition resources per tenant. For example, operate a fleet of virtual machines that all run the same application code, with each instance dedicated to handling traffic for a specific tenant. On AWS, each virtual machine has an instance profile that lets it run with a specific IAM role. If you create an IAM role for each tenant, you can make sure that role only has access to the silo for a specific tenancy.
Silo partitioning is easy to explain and provides strong isolation, but it’s difficult to optimise for cost. If you have a tenant that makes only a few requests per hour, you’re still running at least one instance all that time —more likely, you’re running several to ensure availability.
You can use technologies such as Fargate to cut the size and hourly cost of those silos; a “long tail” of low-traffic customers will mean you’re spending a lot on idle compute. If your workload suits it, you can go further and use a set of Lambda functions, one per tenant, to run the security-critical parts of your application. This also saves costs if different customers have different access patterns: if a tenant never calls a particular Lambda function in their silo, that Lambda won’t cost you anything.
Combined application and platform identity
If your app has tenants, it’s likely to use authentication. If your app lets users log in with either OAuth 2.0 or SAML 2.0 Binding, you can integrate end user with the access controls for cloud components using AWS Cognito. That integration lets code running on end users’ devices have access to the cloud infrastructure for that specific tenancy. Implementing this means all of the application code runs client side: you don’t need to manage any compute.
The basic idea is that users continue to log in to your web or mobile app using either OAuth or SAML Binding, and then the application code on their device calls into an AWS API to get access tokens. Those tokens grant the exact fine-grained access for that end user to access cloud services such as Amazon S3.
This means you’re relying on AWS IAM to enforce access. Switching to AWS IAM means that the enforcement part of your app benefits from AWS’ levels of management and scrutiny — including PCI-DSS compliance and ISO 27001 information security certification.
I’ll explain how to federate an existing identity provider (IdP) with Cognito. You can also use AWS Cognito to manage identities in your application; this is a good choice if you don’t already use an IdP you’re happy with. If you’re currently relying on well-known services such as Google or Facebook for end-user logins, it might not make sense to switch.
Federate with Cognito
Let’s say your app already lets end users login with Google. You can create an identity pool in Cognito; the Terraform code for that looks like:
# set local.google_oauth_client_id to the client ID from Google
resource "aws_cognito_identity_pool" "example_sass_app" {
identity_pool_name = "example_sass_app"
allow_unauthenticated_identities = false
supported_login_providers = {
"accounts.google.com" = local.google_oauth_client_id
}
}
resource "aws_cognito_identity_pool_roles_attachment" "example_auth" {
identity_pool_id = aws_cognito_identity_pool.example_sass_app.id
roles = {
"authenticated" = "arn:aws:iam::123456789012:role/cognito/example"
}
}
For a demo, you can use your existing OAuth client ID. In production use, especially if you have a mobile app and a separate web client, Google recommend that you use the OpenID integration with Cognito instead and have a different client ID for each family of client app.
In the Terraform code, the second resource attaches an existing IAM role to the identity pool. That attachment is the key concept that lets you connect application identity to your AWS infrastructure and apply access controls. This doesn’t just map all your users to a single role though. In an IAM policy, you can use cognito-identity.amazonaws.com:sub to distinguish different users that all assumed the same role.
Coming back to Amazon S3, you can set up a bucket policy that looks like:
{
"Version": "2012-10-17",
"Statement": [
{
"Action": ["s3:ListBucket"],
"Effect": "Allow",
"Resource": ["arn:aws:s3:::your-bucket"],
"Condition": {"StringLike": {"s3:prefix": ["${cognito-identity.amazonaws.com:sub}/*"]}}
},
{
"Action": [
"s3:GetObject",
"s3:PutObject"
],
"Effect": "Allow",
"Resource": ["arn:aws:s3:::your-bucket/${cognito-identity.amazonaws.com:sub}/*"]
}
]
}
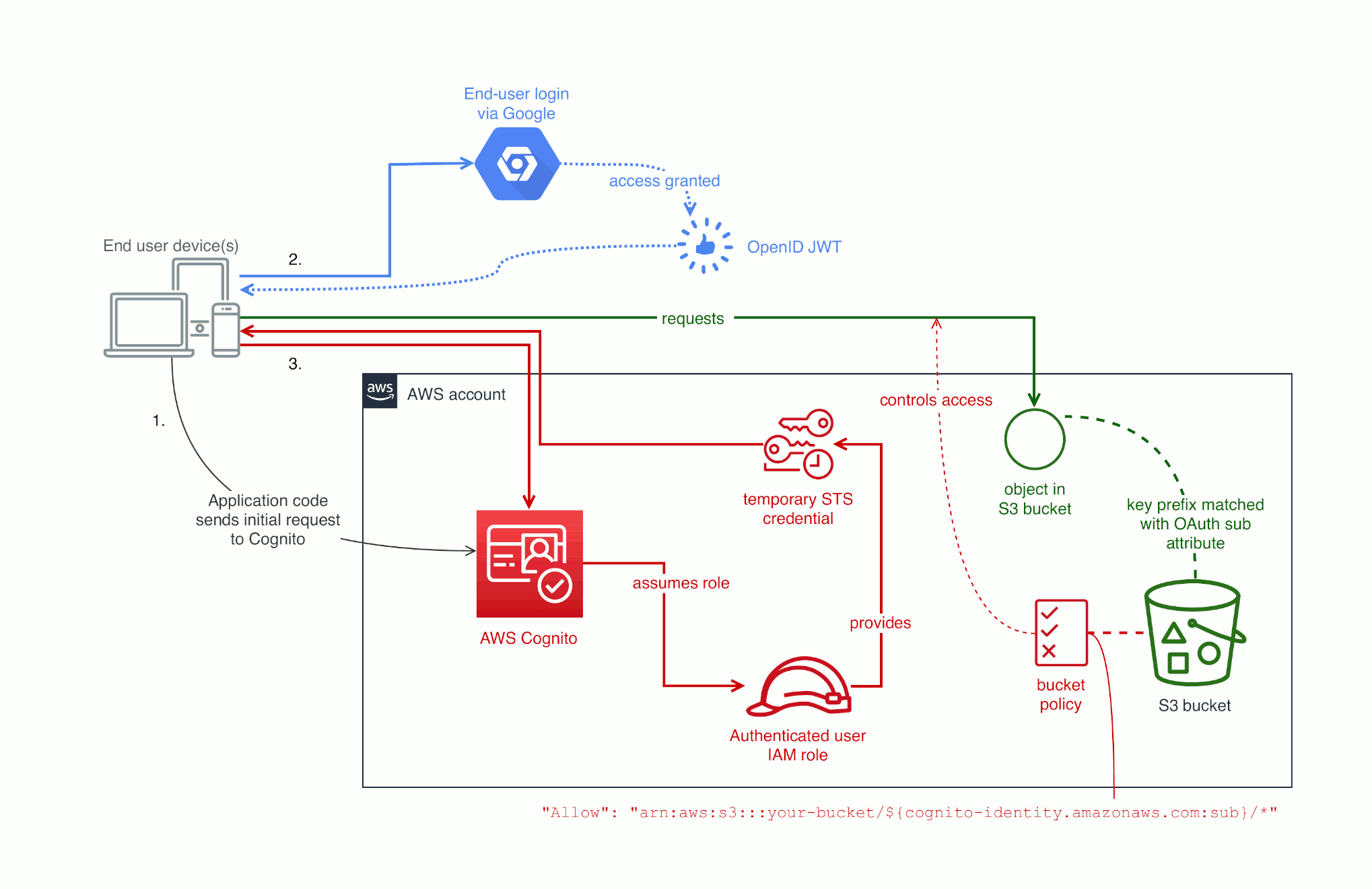
Grant access to an S3 bucket based on a user's cloud identity
What if you have multiple end users per tenant, and you want to make sure that an end-user doesn’t access documents from a different tenancy? You can implement that on AWS with a broad role that you narrow via a Lambda. For example, you can set up a Lambda that maps federated users and lets those end users assume an IAM role with a permissions boundary (read/write, or read-only). When assuming that role, the Lambda sets the RoleSessionName to the end user’s tenant ID. At the moment, AWS does not let you enforce this kind of restriction via IAM policies alone.
Here’s a diagram of how that can work:
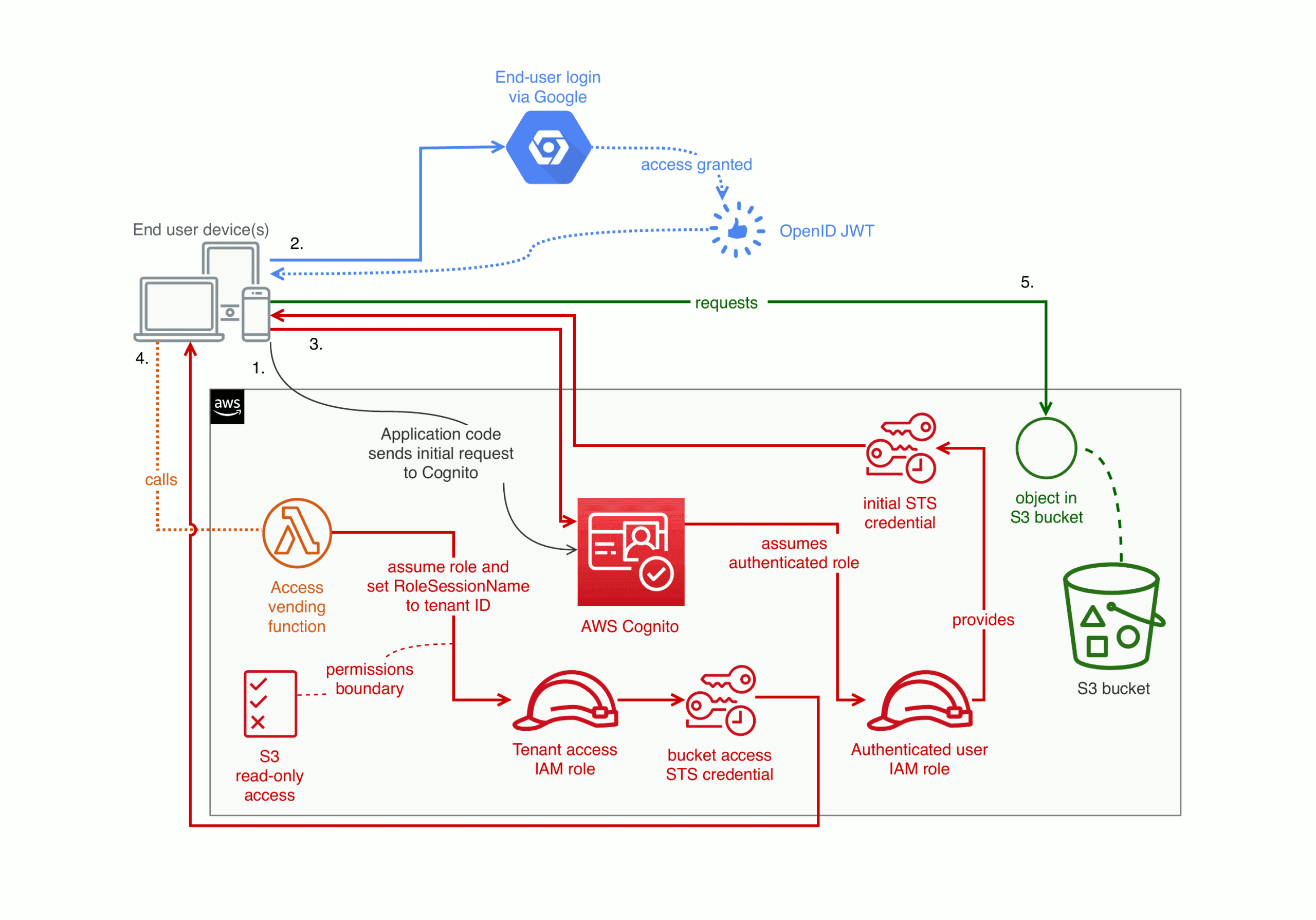
Grant access to an S3 bucket based on a user's application tenancy
This final example is more complex. To implement this you need to use AWS internal user IDs to prefix object keys (if you already had a bucket with different keys, you would need to migrate).
{
"Effect": "Allow",
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::your-bucket/tenants/${aws:userid}",
"arn:aws:s3:::your-bucket/tenants/${aws:userid}/*"
]
}
In the example policy above, IAM expands ${aws:userid} to something like AROA7GWA2GKK6M7ADVF3Q:_example-tenant_ where AROA7GWA2GKK6M7ADVF3Q is AWS’s internal canonical user ID for the tenant access IAM role. The part after the colon is the RoleSessionName that the Lambda sets when it assumes the role.
With this architecture, you can optionally use an IAM permissions boundary to limit the set of actions available to an end user (for example: the Lambda you decide which end users are allowed to PUT objects into the bucket and which are only allowed to list and GET those objects). If you control the identity provider, you could work out what access to grant based on OAuth claims or SAML assertions.
You still get to benefit from access enforcement via STS & IAM, and that means:
- you’ve let someone else take care of access enforcement, putting it on the AWS side of their shared responsibility model.
- (for this example) the code that controls tenant isolation lives inside that one Lambda; potentially, only a few lines long. Less code to run means less code to audit.
- For performance- or latency-critical workloads, your end users can access cloud services like S3 or DynamoDB directly. Once the user is logged in and authorised there’s no overhead for running server-side code, because all the code in that path runs either on the client or inside the AWS cloud.
If the end users to your application authenticate to a major provider such as Google or Facebook, and the access checks you use are the ones built in to Amazon S3, you’ve substantially limited the amount of security critical code you need to write and validate.











