
If you have to decide between running a service or paying for a managed version, you should usually pay for the managed version. Sometimes, you should hide that you did.

Using a serverless approach to application design, you can tie a few cloud services and, most likely, some of your own client-side code into a really useful app. Let’s say you’ve done this and you didn’t use any compute instances at all. I’m going to explain some ways this can catch you out.
Here’s a simple API that I made up, and infrastructure to run it. The API provides a list of rendered GIFs, and clients can send in a text string to get it rendered into new GIF:
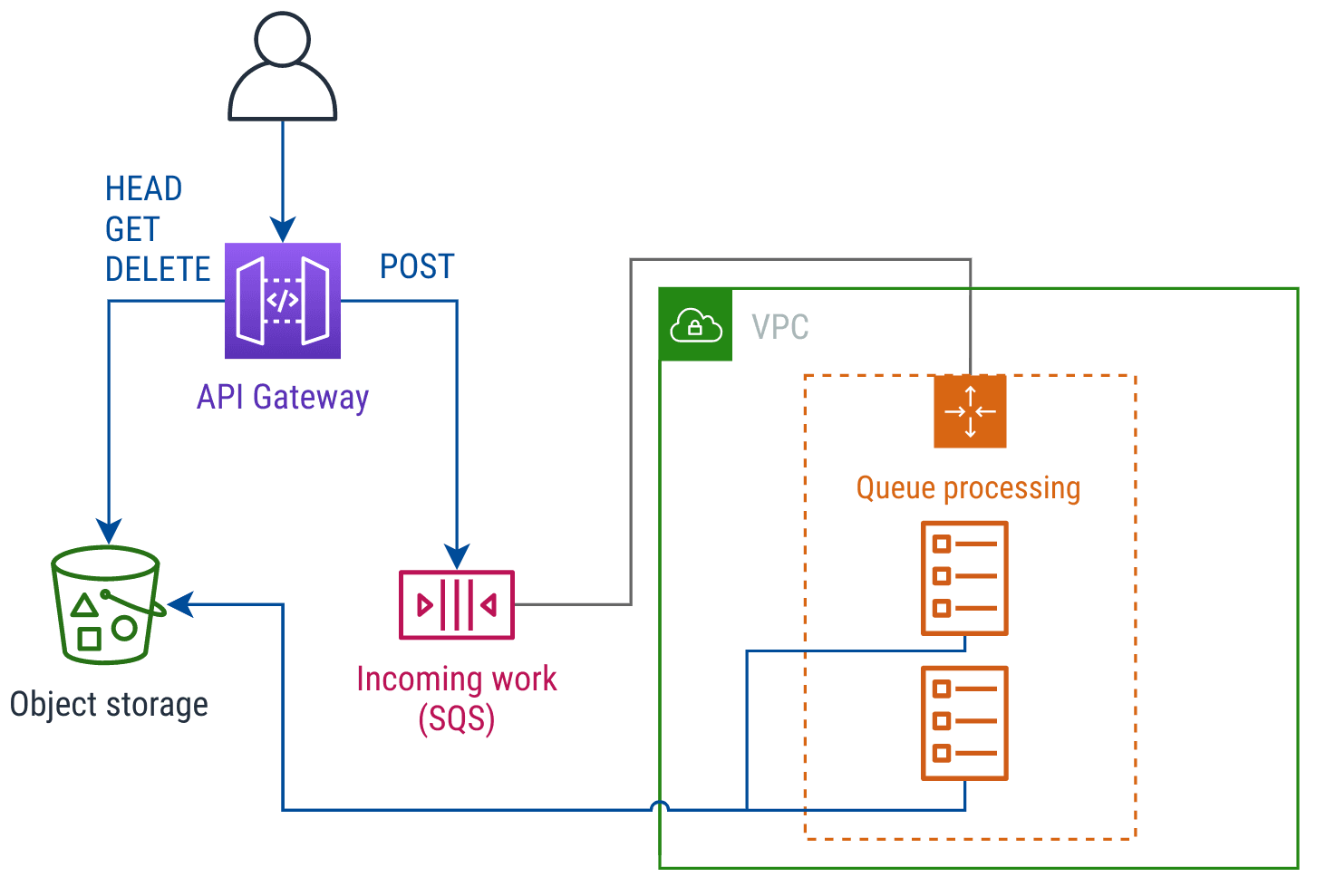
Example GIF rendering infrastructure
In this example, clients send POST requests to the API to add a new
message. If that text string hasn’t already been rendered on top of a
GIF, the container tasks (in orange) render a new GIF and store it into
Amazon S3.
Now, imagine that you’re bringing your own thing into the mix. That GIF-rendering service can scale out no problem; the trouble it, as the user base grows, the service needs to change too.
Some changes are easy. PNG or WebP support? Get implementing. It needs rate limiting? Built in to API Gateway. It needs rate limiting per user? Now the service needs a way to authenticate users and track that limit based on their identity.
A while later, you the product owner decide that rendering the text over a random public-domain kitten photo is not enough. In fact, you decide to try a machine learning approach to select candidate images and to suggest backgrounds for supplied text.
Buy or build?
Here’s a decision point. Do you make your own service or use a cloud API? My advice: whichever you choose, keep that choice a secret from the rest of the code. Then pick the one you like best right now.
I don’t mean keeping secrets like you see in cinema: big heavy doors, guards, fingerprint scanners. All I’m recommending is to hide the implementation just enough so that if you did swap the implementation out, you don’t need to change the rest of your code.
Leaving yourselves room to switch means the decision doesn’t have to be right first time. If you tried extending an open source project and found it frustrating, you can switch to a cloud service – on AWS you have Rekognition as a managed offering, or you can use SageMaker.
Switching sides
When something is key enough to the workload that you’d consider building it yourself, bear in mind that you have another option: a rival vendor.
Most of the time we see our customers favouring just one cloud infrastructure supplier, and we think that’s almost always the right choice. Cloud services are APIs – at least, all the good ones are. You want object storage? There’s an API for that. You want to manage a fleet of containers? There’s an API for that too.
Each vendor’s API is incompatible, with big differences between the major players (AWS, Azure, Google) – and little prospect of things changing on that front. As a developer interacting with infrastructure APIs, you’ll have an easier life picking just one and sticking with it.
Imagine you want to know what colours are used in the photo, so the text is a good contrast. You find an API that does just what you need when you try it out, but it’s from a different supplier. This kind of thing is good reason to add a second supplier. It’s also the kind of detail to keep hidden from your other code.
Concealing the details
If you integrate a foreign API into an app written for AWS, hide details such as access control and authentication. How much you hide is up to you (but I’ll give you some tips).
If there’s already a client library from the SaaS vendor, great. Use it but think about abstracting it. I’ll use the same example I already mentioned, finding colours for an image – imagine the response looks like:
{
"apiVersion": "2020-04-02",
"analysisDate": "2020-10-12T14:17:05+00:00",
"matchAlgorithm": "http://example.com/ld/algorithm#foo",
"colorMatches": [
{ "name": "red", "hexCode": "#fd0413" },
…
]
}
I’d make an internal API that passes along colorMatches as-is, because
that’s important – and leave out the other details. Making an internal
API doesn’t mean running a webserver: you can start off with a client
class that passes the data back as a native struct.
The more implementation information you hide from the rest of your app,
the easier it is to switch.
Secrets and tokens
There are lots of ways to call client code for APIs, including how you
pass in passwords or other secrets for authentication. This is an area
where looking ahead can save you time and effort.
Sometimes, you have an API with a single, shared secret that you use as
a bearer token. Really easy to use – or misuse. Have a think about the
impact if it gets leaked. For the GIF example, the worst case is probably
just that people can’t draw funny pictures. It’s still worth making the
effort to separate configuration from code, but I wouldn’t worry further.
Now imagine a different story – the API token is for image classification, but the same API token also lets you access all the other supplier APIs. This isn’t some made-up example: you can set that up on AWS with IAM access keys, or even account-level root credentials. Make those public and instead of a small bill for image classification you could be looking at a big bill for Bitcoin mining, plus a headache after sorting it all out.
The major cloud vendors offer service accounts or roles, with access control rules and short term tokens. If you use a smaller supplier that doesn’t, here’s a sketch of how to keep those tokens secure with a proxy:
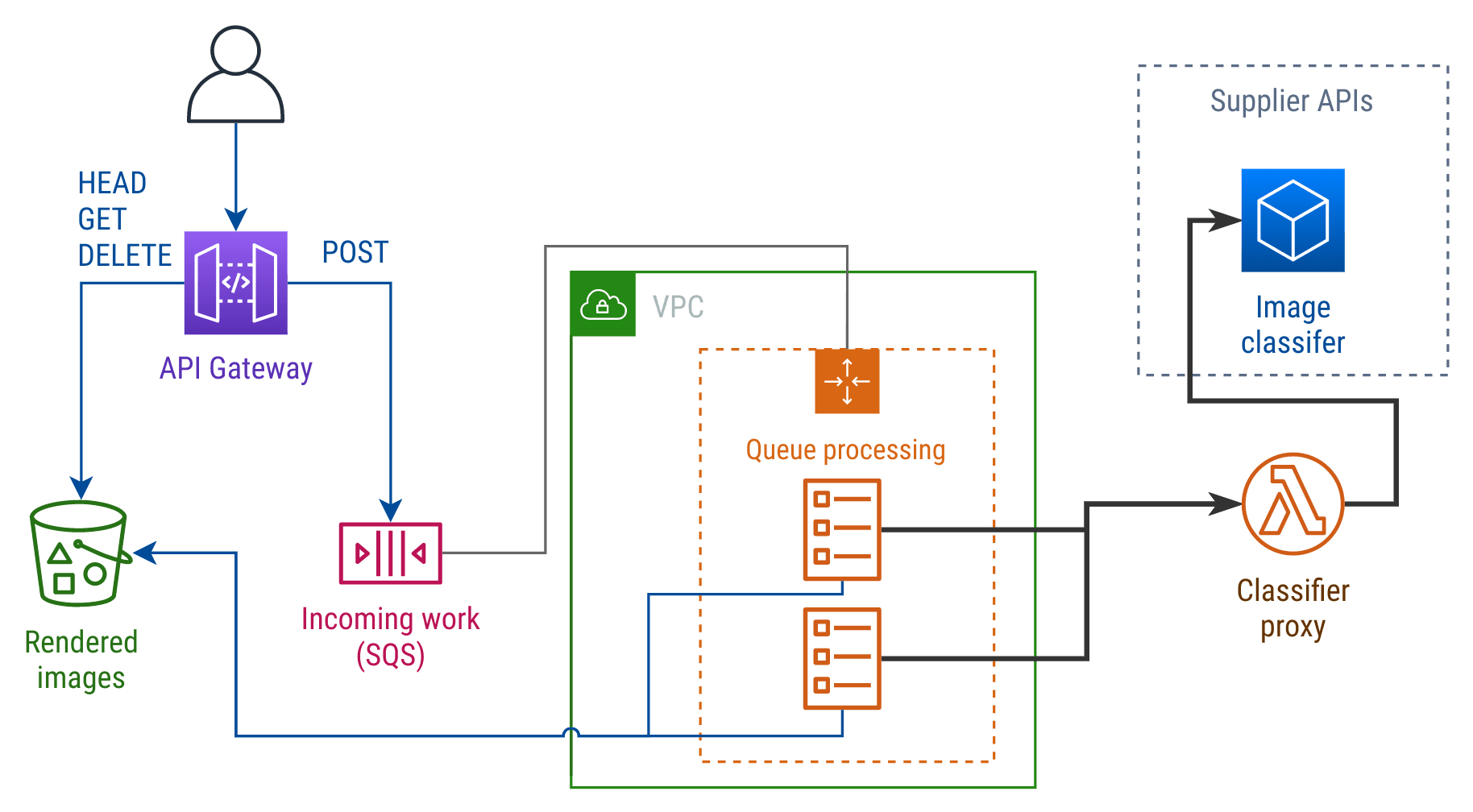
To control where the supplier API token gets used, you can take the same API you already expose to the rest of your app and revise your client wrapper. Now, instead of invoking it locally, the client wrapper uses the ECS tasks’ IAM role to invoke a Lambda function.
The Lambda function takes its payload and adds in the API token for the supplier’s API. This way, only that Lambda has access to the API token (you can store it in Secrets Manager and lock down access). The code that adds the API token stays simple and is easy to review.
Stay simple
If you use a database, you might be thinking about portable code – making sure that your app works with, say, Microsoft SQL Server and PostgreSQL, and letting you switch between them at a whim. Most languages have mechanisms like JDBC, PEP 249, etc. Use them unless you have a really good reason not to.
It doesn’t have to be perfect. Say you started with SQL Server and then later wanted to switch. OK, you’ll have some SQL statements to tweak and driver details to update. That’s significantly less work than if you were switching between different query languages, and it’s OK to put off the work to make for perfect compatibility until a time when you actually need it.
Whether you’re making a client for a custom protocol, or calling the simplest web APIs, stop once the basics are covered: you could change the parts of the app that consume the API, without a major rewrite. If you’re putting in a big abstraction layer, make sure it’s for a component that provides real value to your end users, and that the abstraction helps manage a genuine risk.
Downtime
What if it breaks? Cloud APIs can and do fail. So can your internet connectivity between suppliers. Slow responses can matter to your customers just as much as outright errors.
When that happens, it’s often more valuable to make the client end of things handle the error than to make the server end really resilient. That’s true whether it’s an essential element or an optional enhancement.
Making your app play well when the database is down means you give your users the best available experience when that does eventually happen. In your automated testing, you can go as far as to test for behaviour not just when everything works well but also when responses take an extra ten seconds (the test might expect an error response rather than an exception).
Rather than expose a service directly, adding a wrapper lets your code implement the business logic that models the behaviour your clients want. You can track an OpenMetrics counter with a meaningful label, or fire off a notification each time it happens.
Again, this is a good fit for the high-impact aspects of your app and its behaviour. If a metric lets you alert when a business outcome is at risk, it’s important to have a layer in your code where you can track that metric.
Wrapping up
When there are valid alternatives to a particular technology, think about hiding which one you chose. The more that this technology is key to delivering customer value, the more it’s worth considering whether to keep your options open.
To leave room to switch things out, the main step to take is to limit how many components talk directly to that component. If you made microservices, you get the benefit of being able to replace the persistence layer service by service. You also get the overhead of deploying and managing microservices – there’s no free lunch.
In my next article I’ll explain what I call the “modular monolith” pattern: splitting an application into components, and also making it feasible to bundle up those components and run them combined. You get the main benefit people want from microservices, without most of the overhead. Stay tuned!











