
Please note that this post, first published over a year ago, may now be out of date.
At The Scale Factory we’ve been building secure, multi-account AWS infrastructures for a long time - well before AWS Organizations was a thing. Today architects are spoilt for choice with solutions like Landing Zone, Control Tower and, coming soon, the Terraform Landing Zone. All of those let you provision new accounts at the press of a button and Amazon actively encourage us to do so. Your developers want to play with a new service? No problem, provision a sandbox account. Your boss wants to pivot into pet fashion accessories? Fine, here’s a few more. All nicely isolated from the boring, money bringing production workload.
For the most part this is great but you can easily end up with a lot of accounts and with all that goodness comes complexity and operational burden. Current AWS solutions will take you part way there, but there are gaps which you’ll need to take care of yourself. In this post I’ll share some of my experiences building multi-account infrastructures and introduce you to a little tool we wrote which helps fill in some of these gaps: tfctl.
Separate baseline and workload resources
Control Tower and Landing Zone are great at two things: provisioning accounts and establishing a baseline across those accounts. A baseline involves things like setting up CloudTrail, GuardDuty, configuring Service Control Policies and SSO access to the accounts. It’s mostly boilerplate infrastructure stuff. It’s important but not directly related to your business goals. Then you have what I’ll call “workload” resources. This is infrastructure directly related to your business. It could be containers running your website on Fargate, S3 buckets for static assets and so on. There is a significant operational difference between managing baseline and workload resources.
Baseline, once established, usually won’t change very often and it’s not something your developers need to particularity worry about (or even see most of the time). Because it involves foundation resources, such as IAM users for SSO access, it often requires high levels of privilege to manage. Workload resources on the other hand can change frequently and will likely be in direct contact with developers.
Whatever tools you use to build your infrastructure I generally recommend keeping those two concerns separate (as in separate git repos, change deployment pipelines etc.). It’s good for security and keeps the boilerplate clutter away from the stuff that’s generating real business value. It helps developers focus on what matters and it lowers their cognitive load during day to day operations.
Managing workload resources with Terraform
Let’s assume for the rest of this post that you have a baseline automated with Control Tower. How do you go about managing your workload resources? If you are a CloudFormation shop you’d probably want to have a look at using stack sets. If you feel more at home with Terraform, you can use it too. I will concentrate on Terraform here since it’s what I generally prefer to use (I like the quick development feedback loop).
However, there are a few things I’d like Terraform to do which it doesn’t quite do out of the box yet:
- Discover accounts automatically — since account creation is automated in Control Tower it would be a shame to manually manage this in Terraform. An easy way to discover accounts is through the Organizations API in the primary account.
- Set up state tracking and account boilerplate automatically — in essence I want new accounts to just show up in Terraform and be ready to work with.
- Run across accounts in parallel — it’s easy to make new accounts and chances are you’ll end up with a lot of them. Applying changes sequentially doesn’t scale beyond a few accounts, and waiting for resources to apply can be a real productivity killer. Since most of the time Terraform is waiting for AWS to do its thing we can get substantial gains from running multiple Terraform instances concurrently.
- Manage groups of accounts — thinking in terms of individual accounts is not going to scale well either. Imagine you want to add an S3 bucket to 20 accounts. Doing it individually is likely to be time consuming and not very DRY (Don’t Repeat Yourself).
- Run locally and in a CI/CD pipeline — in the early stages of developing Terraform code I like to run it locally against a dev account. It gives me a quick feedback loop which helps churn things out quicker. Later on the delivery process needs to be automated using a pipeline so that changes can be promoted through test environments with change control and code reviews along the way.
To fill in these gaps we wrote tfctl, a small Terraform wrapper. It talks to AWS Organizations to work out the Organization Unit (OU) and account topology. Organization Units are a way of grouping accounts together in a hierarchical structure. OUs are used by tfctl to assign resources and configuration to groups of accounts. An example organization structure could look something like this:
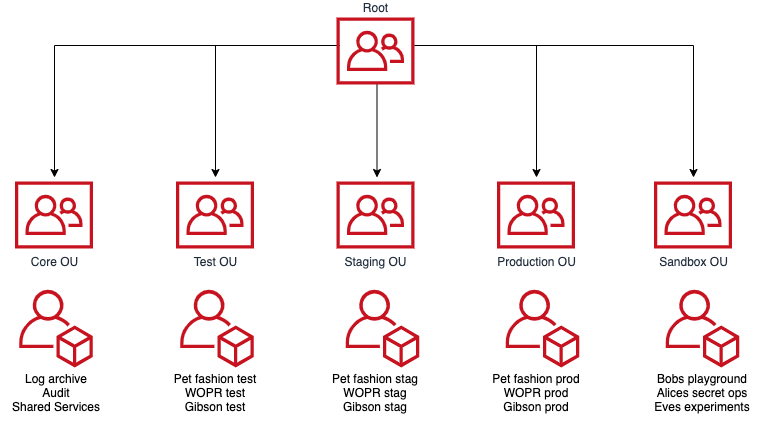
You can have more layers if you want, but not all AWS services support that yet. Landing Zone does, Control Tower doesn’t but I suspect it will soon as the feature gap between the two narrows with time.
Configuration concepts in tfctl
Configuration is read by tfctl from two sources: AWS Organizations and a yaml config file. The config file is where you can map Terraform resources to groups of accounts.
Say you have a Terraform module which creates a DynamoDB table. You can deploy it to all accounts in an organization by assigning it to the organization root:
organization_root:
profiles:
— example-dynamodb-module
or you could deploy it to accounts in a specific OU:
organization_units:
test:
profiles:
- example-dynamodb-module
It’s also possible to assign resources to individual accounts:
account_overrides:
unique-account:
profiles:
- example-dynamodb-module
In addition to modules (profiles) you can also set arbitrary configuration data in the config file. This data is available to Terraform profiles through a special ‘config’ variable.
organization_units: test:
data:
table_name: "test-table"
profiles:
- example-dynamodb-module prod:
data:
table_name: "prod-table"
profiles:
- example-dynamodb-module
Configuration is merged by tfctl from the different organization levels so it’s possible to set default values and overwrite on exceptions keeping your configuration DRY:
organization_root:
data:
table_name: "default-table"
profiles:
- example-dynamodb-moduleorganization_units:
test: {}
staging: {}
prod:
data:
table_name: "prod-table"account_overrides:
snowflake-test-account:
table_name: "imspecial"
In the above example all accounts will inherit example-dynamodb-module from the organization root. Test and staging OUs will use the default table name but prod OU overrides it to prod-table . We also have a special “snowflake” account in test which overrides the table name. If you have ever used Hiera with Puppet before, this will be a familiar concept. You can view the fully merged configuration with tfctl -s
Running locally
So how do we run this thing? To execute Terraform across all of your accounts you’d run:
tfctl --all -- init
tfctl --all -- plan
tfctl --all -- apply
Looks familiar, right? Anything after -- is passed to Terraform so all the usual Terraform switches are available. Once it’s running tfctl will discover accounts, generate any boilerplate Terraform configuration and start executing in parallel across the estate.
You can restrict the execution to a specific OU:
tfctl -o test -- plan
Or individual account:
tfctl -a snowflake-account -- plan
If you have a nested OU structure such as:
/HR/test
/HR/prod
/Finance/test
/Finance/prod
You can filter on the OU path using regular expressions:
tfctl -o '.*/test' -- plan
The above will match test accounts in both HR and Finance parent OUs.
You can find more examples in the git readme.
IAM permissions
You need to provide tfctl with read-only access to AWS Organizations in the primary account for account discovery. It also needs access to state tracking resources: an S3 bucket and DynamoDB table. Finally each account needs a Terraform execution role which should be set up as part of your account baseline.
CloudFormation bootstrap templates are available to make setting this up easier.
CI/CD pipeline
When writing tfctl we followed some of the practices outlined in “Running Terraform in Automation” so it should work fine with most CI/CD systems. As an example I’m going to cover AWS CodePipeline and CodeBuild here. The benefit about using AWS services for this is that you don’t need to share credentials with a third party or store them anywhere. Instead you can give CodeBuild a service role which permits it to assume the roles tfctl uses. This means tfctl will take care of assuming roles roles automatically, making cross account operation nice and easy.
The Terraform pipeline is usually set up in a shared management account (often called “Shared Services” in AWS nomenclature) and gets triggered from commits to master branch of your project repository. From there CodePipeline triggers CodeBuild jobs which execute tfctl in Linux containers, then tfctl takes care of executing Terraform. A typical CodePipeline stage would look something like this:

Here it deploys changes to test and staging. It runs a plan concurrently in both environments to speed things up but applies one environment at a time. Within each environment changes are applied to accounts in parallel. The pipeline will abort on any failure.
CodePipeline copies the entire project directory as an artefact between actions to ensure exactly the same code is run during apply as it was during plan. It also saves a plan file for use during apply. If anything changes on the AWS side in between plan and apply, the plan will become stale and apply will bail out.
When deploying to production we usually have a manual approval gate between plan and apply so that plan can be reviewed and approved. Another nice benefit of using CodeBuild here is easy access to logs. You can click on the “Details” link in the pipeline to view the plan output.
Because of parallelisation this pipeline runs fairly fast. In a set up with four environments (test, staging, production and core) and 12 provisioned accounts it takes less than 10 minutes to go through everything. In comparison a Landing Zone deployment pipeline, which is a mix of CodePipeline, Step functions, Lambdas and CloudFormation, can take an hour just to do a no op.
Conclusion
First of all, congratulations for making it this far! I hope this helped you have a better understanding of why and how to separate account baseline and workload resources, and how tfctl can be used to help with this. We also touched on how to organize accounts into Organization Units.
If you’d like to have a play with tfctl, we have a step by step guide for using it with Control Tower here:
Keeping on top of all the latest features can feel like an impossible task. Is practical infrastructure modernisation an area you are interested in hearing more about? Book a free chat with us to discuss this further.
This blog is written exclusively by The Scale Factory team. We do not accept external contributions.