Please note that this post, first published over a year ago, may now be out of date.
Software as a service (SaaS) allows your customers or end-users to use your application over the Internet. With SaaS, you provide a software-based solution that covers your customers’ needs in a particular area, and you bill either based on time (eg: a fixed cost per user, per month) or by use (eg: a fixed cost per image render).
If you have multiple customers that each have their own set of end users, then often each customer wants the system to work as if they are the only tenant. There are essentially three ways to divide this up:
Individual platforms
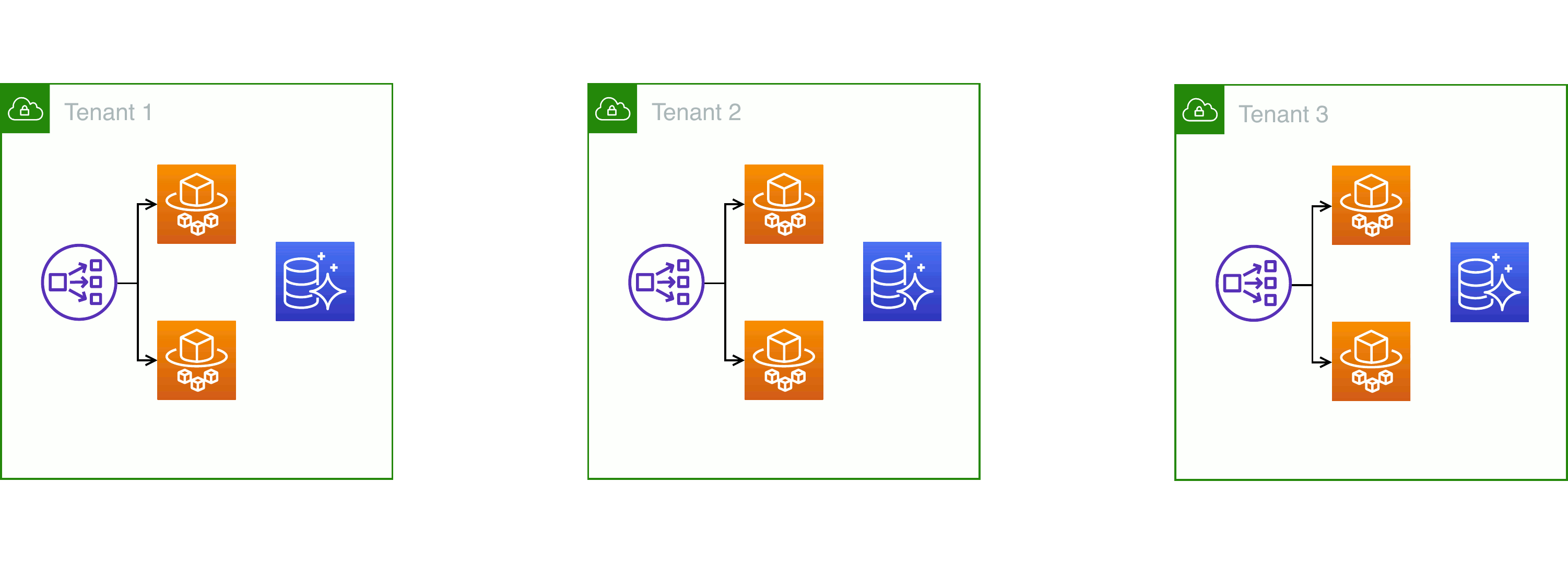
Silo-style: one VPC per tenant, no resource sharing
The straightforward way to achieve that is to create a separate deployment of your entire system each time you take on a new customer. Sometimes, this approach is called a “silo” — named after the isolation between different nuclear missile launchers and their control rooms.
Pooled resources
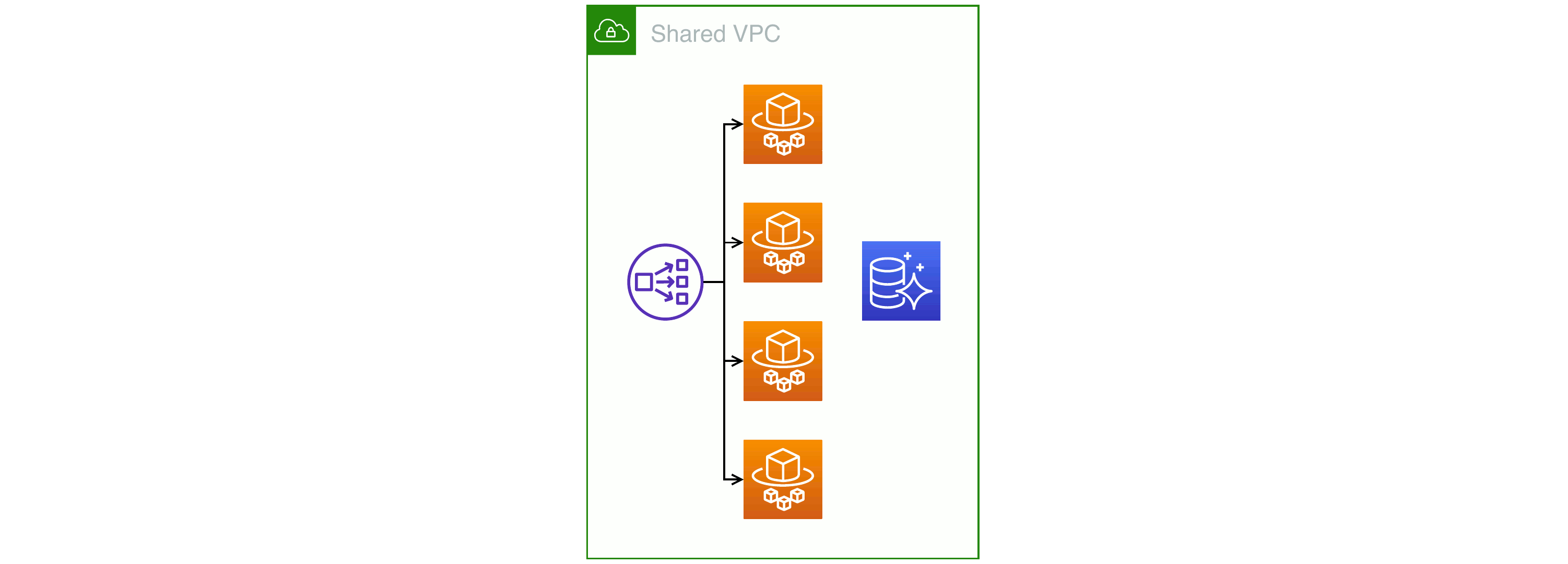
Pool-style: all resources shared between tenants
The opposite of having one deployment per client is to run a single infrastructure that serves all tenants. This approach to cloud services is almost as old as commercial computing itself; early computers were so expensive that only the largest customers could afford their own. Businesses such as travel agents shared access to a central mainframe that handled transactions for all the service provider’s clients.
You might share resources between a subset of your customers. For example: you offer a free tier where you overcommit computing resource and offer only best-effort outcomes, and you also offer one or more paid tiers with an elastic pool of shared compute, automatically scaled to provide an agreed level of service.
Hybrid tenancies
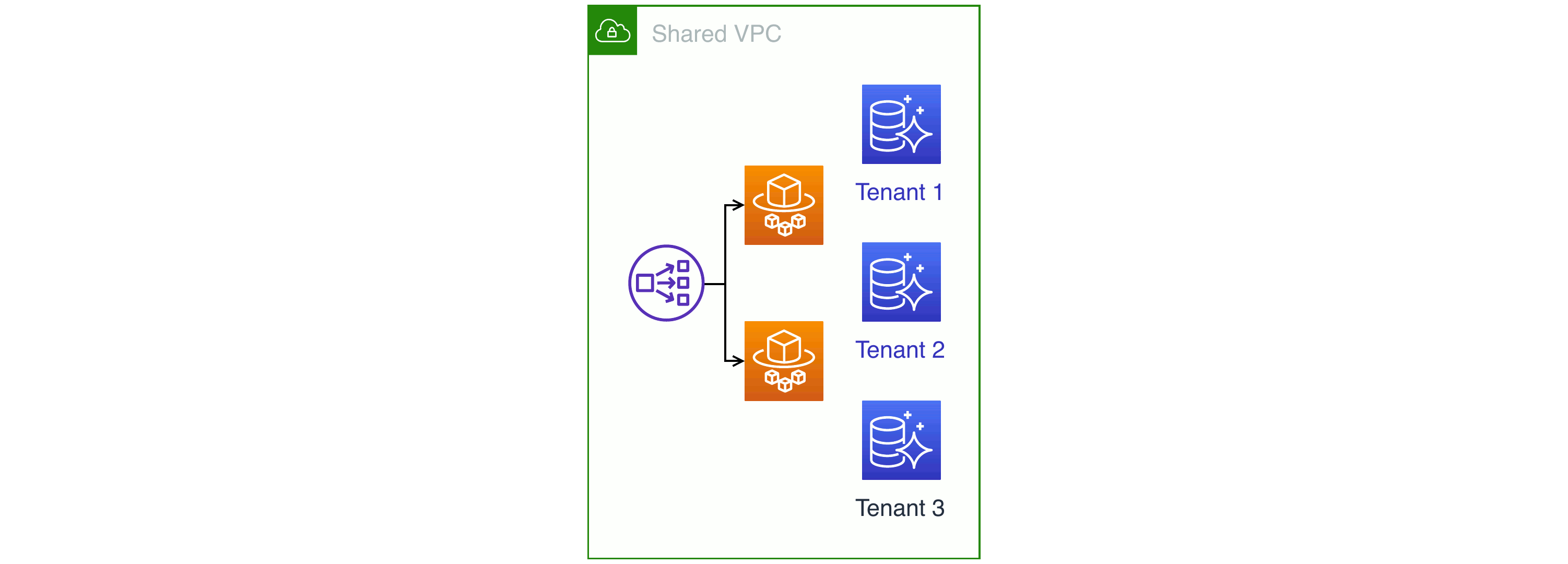
Hybrid: VPC, network load balancer, and Fargate tasks are shared; each tenant has their own Aurora database
Most SaaS providers pick something between the two extremes. For example: you run a platform with most resources pooled, but you run a particular, security-sensitive process inside AWS Fargate as a single task per tenant.
Managed cloud services, such as AWS KMS, let you provide individual resources per tenant (in this example: a KMS customer master key). You can use KMS for per-tenant encryption without having to buy or rent a hardware security module for each customer you enroll.
Sometimes people call this approach the “bridge” model, because it brings together the elements of “silo” and “pool”.
A tenancy that’s right for you
Different organisations will have started from different places.
If your product was always cloud-native, you needed to make some decisions about tenancy before you could even run a MVP (minimum viable product) service. For a minimum product, your typical focus is on removing barriers and finding the lowest effort route to putting your service on the market.
Some firms were offering software and services from a time when PCs were common, but before customers could afford always-on internet access. During that era, applications typically ran as a stand-alone deployment on your customer’s premises. Moving into the cloud, you might first deploy your whole application for each tenant, and later look at migrating components to use a pooled approach.
What you need from your infrastructure also changes throughout time. Let’s say you’re a software-as-a-service vendor that provides financial software, and you run this on cloud infrastructure. Financial records matter a lot to your customers, so durability is essential all year round. You have to balance customers’ craving for features against a preference for stability — especially common with larger clients. Demand for using your app varies through the year, peaking at times like financial year-end.
If people are mainly intermittent users of the app, like that financial services example I just sketched out, you want an infrastructure with enough elasticity that you’re not paying for idle compute. The cost effective way to implement that is with pooling, whether the computing is serverless (AWS Lambda and friends) or runs in a more conventional way such as AWS EC2.
When a single compute context runs code for different tenants, your code is responsible for enforcing isolation. That’s true whether you’re building a daemon for Linux or a function for Lambda: even though a Lambda only handles a single request at a time, the next request might well be for an end user in a completely different tenancy.
You might place some resources into silos because of compliance and legal discovery. Imagine that one of your tenants finds themselves in court, and is called upon to provide verbatim copies of all the data held about them in your systems. If that tenant’s data are mixed with other tenants, you might get a court order that asks for a verbatim dump of the whole resource (for example: everything in a DynamoDB table). Creating a table per tenant makes explaining things legally a much easier prospect.
For SQL databases, AWS Aurora Serverless lets you scale less-used databases to zero. When there are no clients connected, you’re only paying storage costs. That’s a good fit for a free tier, or for services where it’s OK to wait a few moments for a stopped database to start up. It’s also a good choice if you let your customers choose their own service schedule, such as an SLA covering 9AM to 5PM Monday to Friday, and you don’t want the cost of keeping systems highly available outside those times.
Dealing with limits
Another reason for pooling your resources is that some services have quotas. Cloud services like AWS place limits on resources; for example, you have a limit on how many different DynamoDB tables you can have in a single account and region. For some quotas you can ask support for a higher limit; for others, it’s a hard ceiling.
If you deploy your app to AWS with an individual platforms approach, or a near hybrid, you might be thinking of setting up one VPC per customer. We’ve seen our consultancy clients run into trouble with security groups; there’s a hard limit of 10,000 per region. Whilst that might look high, if you need a design that works for hundreds or thousands of tenants then you might find that you either need to limit the number of security groups you use in each VPC, or to adopt another architecture.
Dealing with differences
If you’re running in the cloud, you probably already heard the concept popularised by Microsoft’s Bill Baker: you should treat servers like cattle rather than pets. Guess what? A lot of the same principles apply to SaaS tenancies. The outcome is different but the same approaches make sense, and for the same reasons:
- Use immutable infrastructure where you can. If you can’t make it immutable, make sure your deploys are repeatable. Apart from customer data itself, an instance that serves one customer or group of customers should be identical to other servers handling the same tier of tenancies.
- Build your code into artifacts and use automation to drive your whole platform, so that it’s running your intended release(s) — that’s releases, plural, because you might run different code for different tenants. I’ll talk more about that below.
- Plan for failure. Expect that compute instances, storage resources, entire failure zones can all go offline. When you’ve got an error budget to meet, pooling lets you run more of a given resource (such as application containers) in an economic way, which reduces the impact when one of those items errors out. If you provide each tenant with, say, two containers each in their own availability zone, then a failure there gives that tenant a 50% chance their request gets an error.
I mentioned running different releases. If you can, you should control application behaviour using feature flags. That lets you make sure all your tenants are running on current code, even if you selectively enable features for different tenants at different times. Slack, the instant messaging service, is a good example of this approach. I’ve got accounts in multiple Slack organisations and I noticed that different organisations get new features at different times.
As a vendor, you can use feature flags to run canary-style rollouts that segment your platform either looking at end users across all tenancies, or a fraction of tenancies. You can even pick the approach to suit each rollout. The more tenant customers and end users you have, the more important it becomes to have an effective way to handle feature changes, both for deploying and for reverting in case of problems.
At home in the cloud
My overall point is that there’s more than one way to do it. In the field of IT there are lots of software-as-a-service vendors that face similar, but different challenges. Within the three main options that I outlined for providing multi-tenant services — silo, hybrid, and pool — you have almost countless options and choices.
Deploying to the cloud gives you that broad set of choices. This means you can select the option that balances information security, cost optimisation, performance, and other concerns, to find the right approach for you and your organisation.
Keeping on top of all the latest features can feel like an impossible task. Is practical infrastructure modernisation an area you are interested in hearing more about? Book a free chat with us to discuss this further.
This blog is written exclusively by The Scale Factory team. We do not accept external contributions.